Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.


Unlock real-time Twitter data with Twitter Scraper API such as URLs, hashtags, images, videos, tweets, retweets, conversation threads, followers/following, locations, and more.
No servers to build or code to maintain
Pay only for successful results
Batch requests — up to 10K URLs
Structured delivery: JSON, CSV, XLSX
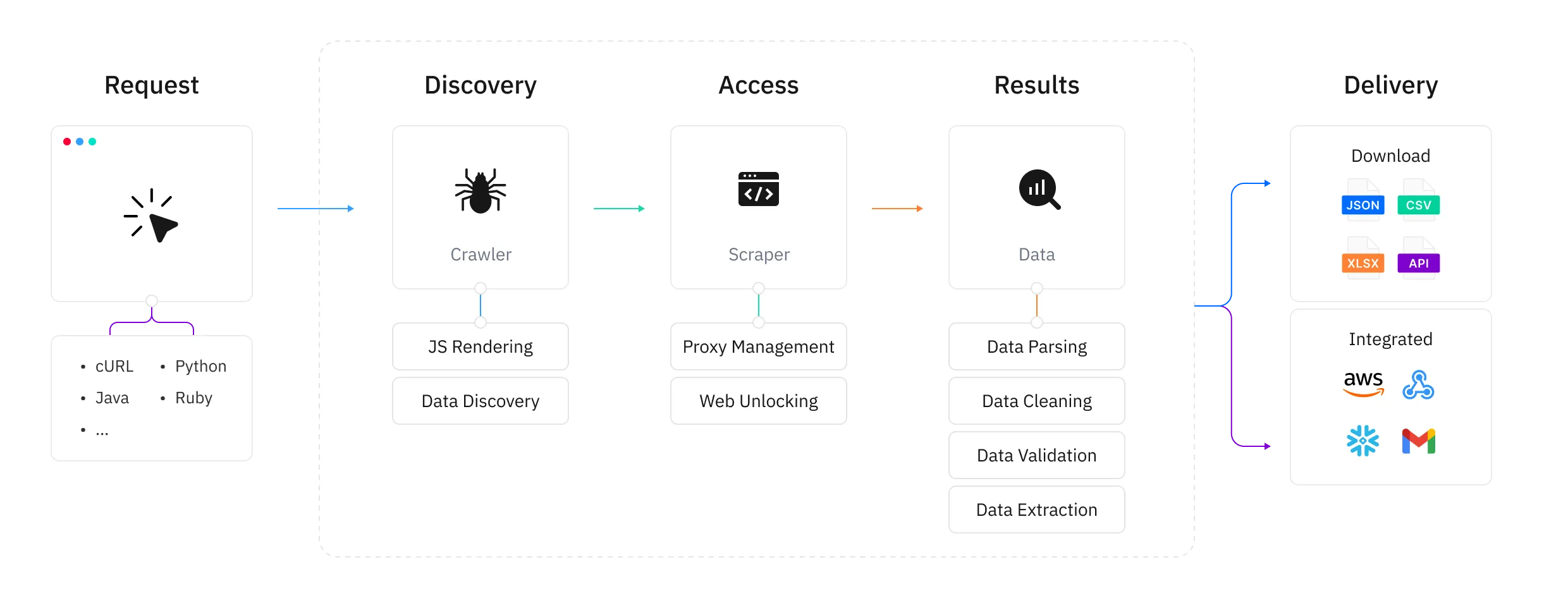
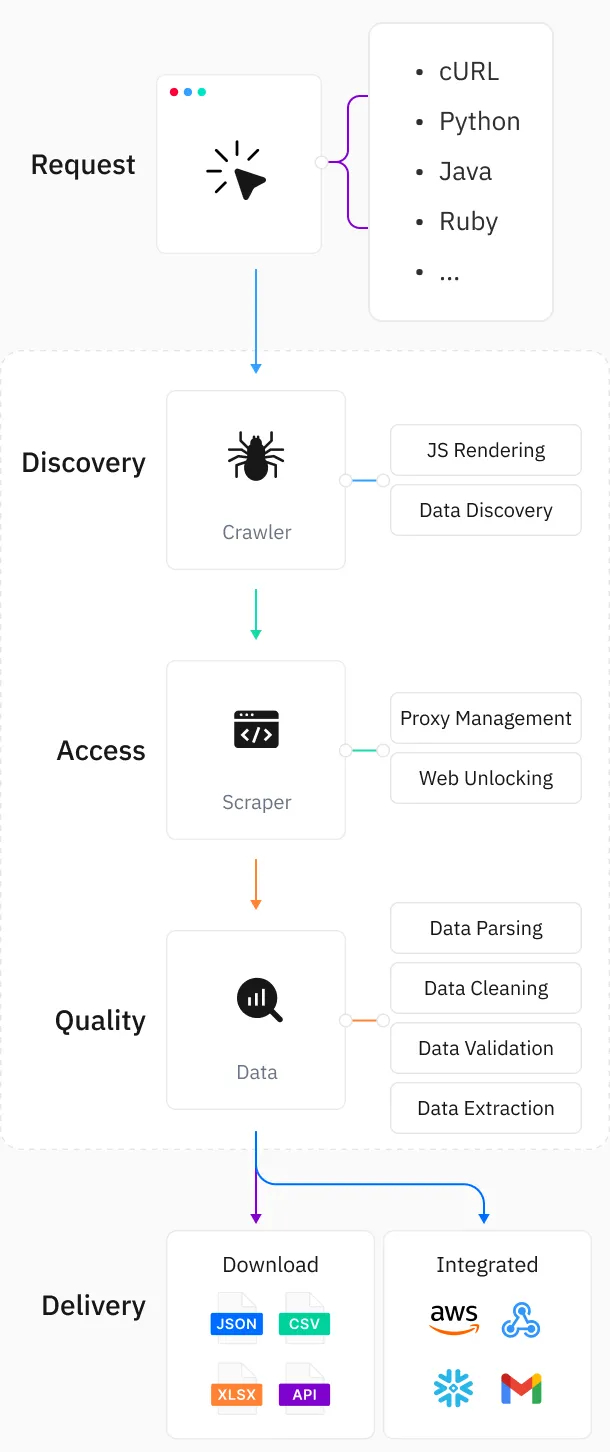
Build your request with our API
Large-scale web scraping via API, supports 9 programming languages.Functional automation
Create a custom scraping scheduler tailored to your specific requirements.Data delivery
Automatically deliver scraped data to your designated cloud storage service.Dashboard-based scraping tool
The entire process is managed within our [Dashboard - Web Scraper] control panel.Flexible & user-friendly
Configure targets and start scraping instantly with scheduled tasks for automated collection.Retrieve results
Download output files directly from the [Dashboard - Tasks].No need to develop or maintain infrastructure—just focus on large-scale web data extraction. The Web Scraper API ensures scalability and reliability.
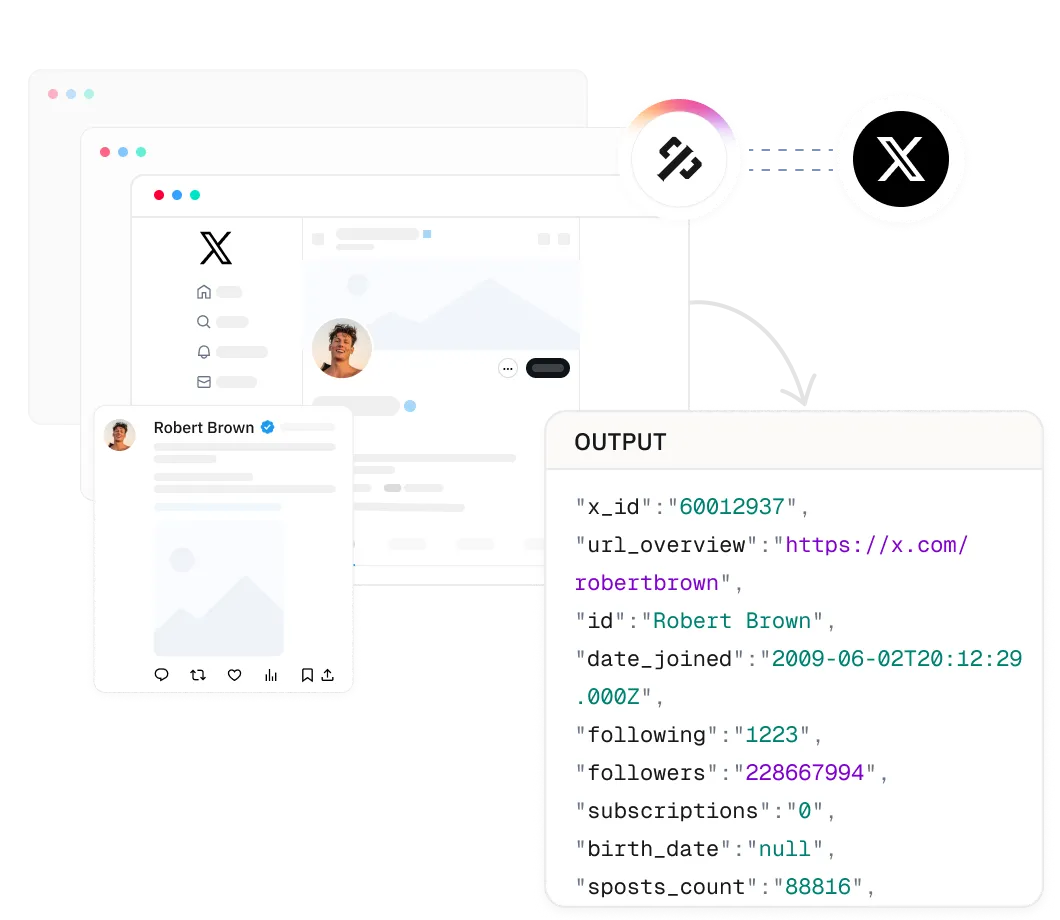
Extract comprehensive user data including unique ID, personal link, nickname, username, bio, verification status, profile image URL, external links, account creation date, follower/following counts, subscription count, location, birthday, tweet count, published tweets, and related accounts.
Scraping method:
Retrieve detailed tweet data covering tweet ID, publisher info, post date, full content, attached media (photos, videos, quoted tweets), engagement metrics (replies, retweets, likes, views), as well as included external links and hashtags.
Scraping method:
Scrape posts from a specific user by username. Returns tweet URLs, IDs, dates, full content, media attachments (images, videos), engagement metrics, hashtags, PLUS publisher insights such as follower count, bio, tweet count, and profile picture.
Scraping method:
Contact our technical experts to get customized data scraping solutions.
Retrieve Twitter(X) information in seconds with a simple API call.
Intelligent IP rotation
Automatic CAPTCHA recognition
HTTP headers
Automatic webpage parsing
Customizable support

Dedicated account manager
Custom structured files
Customized crawling platform
Flexible delivery schedule
Custom data fields
Custom data packages
Streamline workflows, boost automation, and achieve new levels of efficiency.
ML-driven proxy selection and rotation using our premium proxy pool from 190 countries.
Unique HTTP headers, JavaScript, and browser fingerprints ensure resilience to dynamic content.
Automatic retries and CAPTCHA bypassing for uninterrupted data retrieval.
Extract data from several pages at the same time with up to 10K URLs per request.
Transfer data to Amazon S3, Snowflake, Webhooks, or other compatible storage, or access results via the API.
Set your preferred frequency for automated, custom-timed data collection, with results delivered directly to your cloud storage.
Get maximum control and flexibility without maintaining proxy and unblocking infrastructure.
Easy integration, supports high-volume requests, and fully customizable.
Receive professional support in case of any questions or issues.
The single biggest advantage of this tool is its blistering speed and incredible reliability. In market intelligence, timing is everything. While our competitors are still building scrapers, we're already analyzing data. It has fundamentally changed our workflow, allowing us to track brand sentiment and emerging trends in near real-time, which directly informs our client strategy reports.
Sarah Chen
Market Research DirectorFor me, the help it provides is all about depth and agility. I need comprehensive data on competitor audience engagement—not just their posts, but the full picture of likes, shares, and replies. This tool delivers that instantly by URL or username. The straight forward interface means I can run complex data pulls in minutes, not hours, giving me more time for actual analysis and strategic planning.
David Rodriguez
Competitive Strategy AnalystIts biggest strength is the combination of raw power and simplicity. I'm not a developer, but I don't need to be. I was able to get started without any training. I can get clean, structured data on user demographics and content performance so quickly. It helps me build data-backed personas and understand market niches with a level of confidence we never had before.
Emily Watson
Brand Strategy ConsultantBeyond the fast scraping, the stellar customer support is a massive advantage. We had a specific request about data formatting, and the team solved it in under an hour. That efficiency is unreal. This tool helps our entire team by being a dependable workhorse. We set up monitors for campaign keywords and industry influencers, and it just runs flawlessly in the background, fueling our daily insights dashboard.
James Kim
Digital Insights ManagerAs a solo consultant, I need tools that are cost-effective and don't create extra work. This scraper's biggest benefit to me is its efficiency. It's incredibly fast and has zero learning curve, which means I can take on more clients without increasing my technical overhead. It helps me provide clients with robust, data-driven answers to 'what's happening in our market?' faster than ever, which is my entire value proposition.
Linda Patterson
Independent Market ResearcherThe single biggest advantage of this tool is its blistering speed and incredible reliability. In market intelligence, timing is everything. While our competitors are still building scrapers, we're already analyzing data. It has fundamentally changed our workflow, allowing us to track brand sentiment and emerging trends in near real-time, which directly informs our client strategy reports.
Sarah Chen
Market Research DirectorFor me, the help it provides is all about depth and agility. I need comprehensive data on competitor audience engagement—not just their posts, but the full picture of likes, shares, and replies. This tool delivers that instantly by URL or username. The straight forward interface means I can run complex data pulls in minutes, not hours, giving me more time for actual analysis and strategic planning.
David Rodriguez
Competitive Strategy AnalystIts biggest strength is the combination of raw power and simplicity. I'm not a developer, but I don't need to be. I was able to get started without any training. I can get clean, structured data on user demographics and content performance so quickly. It helps me build data-backed personas and understand market niches with a level of confidence we never had before.
Emily Watson
Brand Strategy ConsultantBeyond the fast scraping, the stellar customer support is a massive advantage. We had a specific request about data formatting, and the team solved it in under an hour. That efficiency is unreal. This tool helps our entire team by being a dependable workhorse. We set up monitors for campaign keywords and industry influencers, and it just runs flawlessly in the background, fueling our daily insights dashboard.
James Kim
Digital Insights ManagerAs a solo consultant, I need tools that are cost-effective and don't create extra work. This scraper's biggest benefit to me is its efficiency. It's incredibly fast and has zero learning curve, which means I can take on more clients without increasing my technical overhead. It helps me provide clients with robust, data-driven answers to 'what's happening in our market?' faster than ever, which is my entire value proposition.
Linda Patterson
Independent Market ResearcherContact our technical experts to discuss your data scraping needs.
It's a specialized tool that allows you to programmatically extract publicly available data from the Twitter(X) platform, including user profiles, post content, and engagement metrics, without needing to build and maintain your own scraping infrastructure.
You can extract data easily by providing specific targets like user profiles URLs, tweet URLs, or usernames. The API handles all the technical complexity, letting you retrieve structured data in minutes with just a few simple requests.
Our API is designed to access only publicly available data in compliance with Twitter's terms of service. We strongly recommend users respect data privacy laws and implement responsible data handling practices for their specific use cases.
The API delivers results within minutes, not hours. As one client noted: "While our competitors are still building scrapers, we're already analyzing data." The tool is optimized for high-speed data delivery while maintaining reliability.
The API provides standardized JSON/CSV outputs that easily integrate with most data analysis platforms, BI tools, and custom applications. Webhook support and comprehensive documentation ensure smooth integration into your existing workflow.
As users confirm: "The combination of raw power and simplicity" means you get enterprise-grade data extraction without the development overhead. This eliminates months of building, testing, and maintaining scrapers while providing faster, more reliable results.
Professional APIs handle rate limiting, data structure changes, and anti-bot detection automatically. This ensures consistent data quality and reliability that manual methods or basic scrapers cannot maintain long-term.
Yes, the API supports full automation for ongoing monitoring tasks. You can set up continuous tracking of specific accounts, keywords, or hashtags, with data flowing directly into your dashboards and reporting systems.
We typically offer trial options for new users to evaluate the API's capabilities. Please contact our sales team to discuss your specific needs and available testing options.