Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
700 million independent channels with 6 billion video seeds
Rich video, audio, metadata, subtitles, comments & more
Supports flexible delivery via API and files
Supports full-format downloads with access to the platform's highest quality
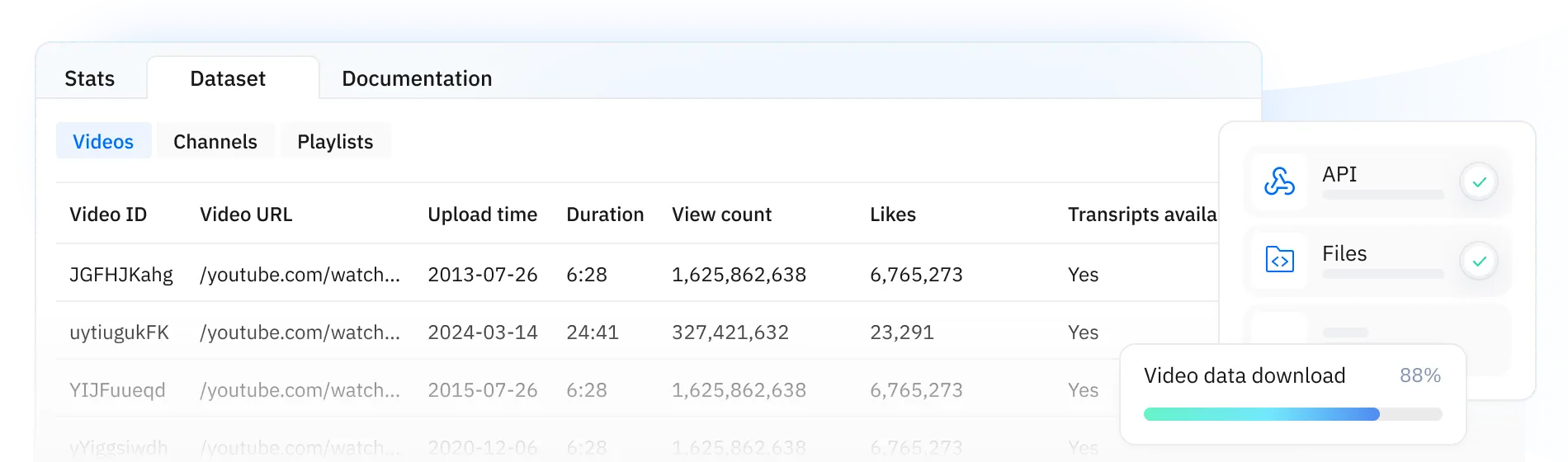
Access validated and curated, pre-collected video datasets
Capture high-quality video/audio
Transcripts and subtitles in JSON/CSV/XLSX
Clean, high-volume video and audio files(mp4 , m4a )
•Enrich speech, vision, or multimodal datasets
•Train vertical AI models or fine-tuning LLMs
Video datasets tailored to your unique AI requirements
Define your content type (video, channel, playlist, movie)
Configure your video/audio quality parameters
Test your settings with a sample batch
•Pre-training initial models
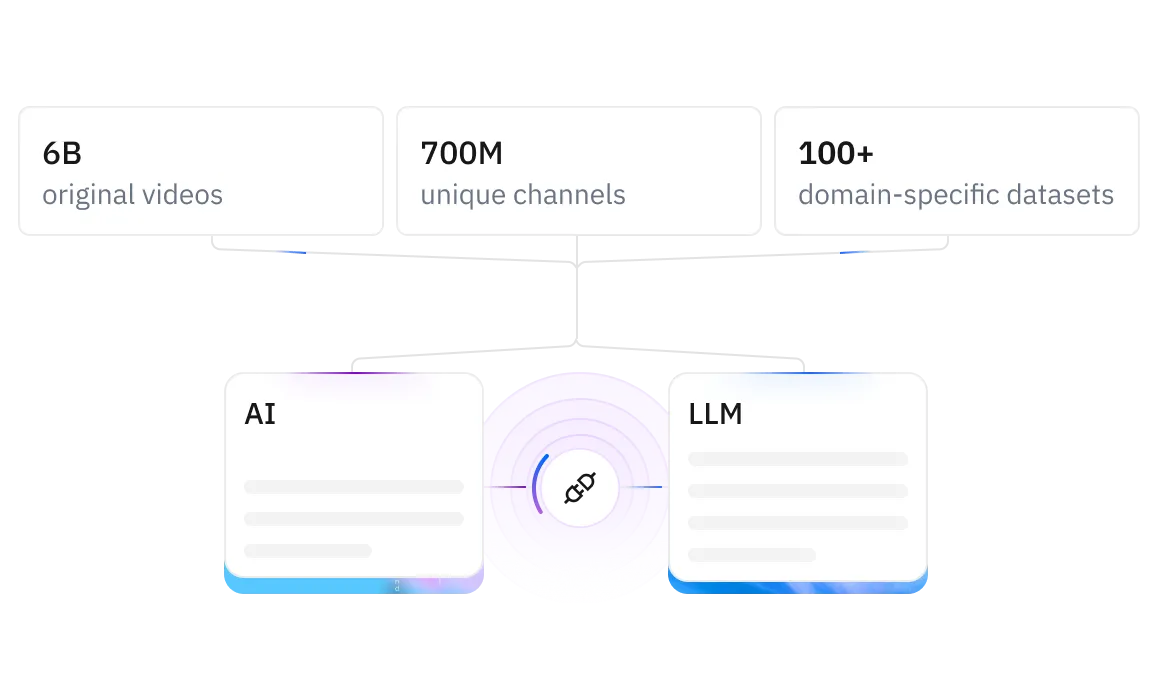
Access 6B original videos from 700M unique channels and 100+ domain-specific datasets—powering vertical AI model training and LLM fine-tuning.
6B original MP4 videos sourced from 700M independent channels
Transcripts, subtitles, and metadata
M4A format audio files
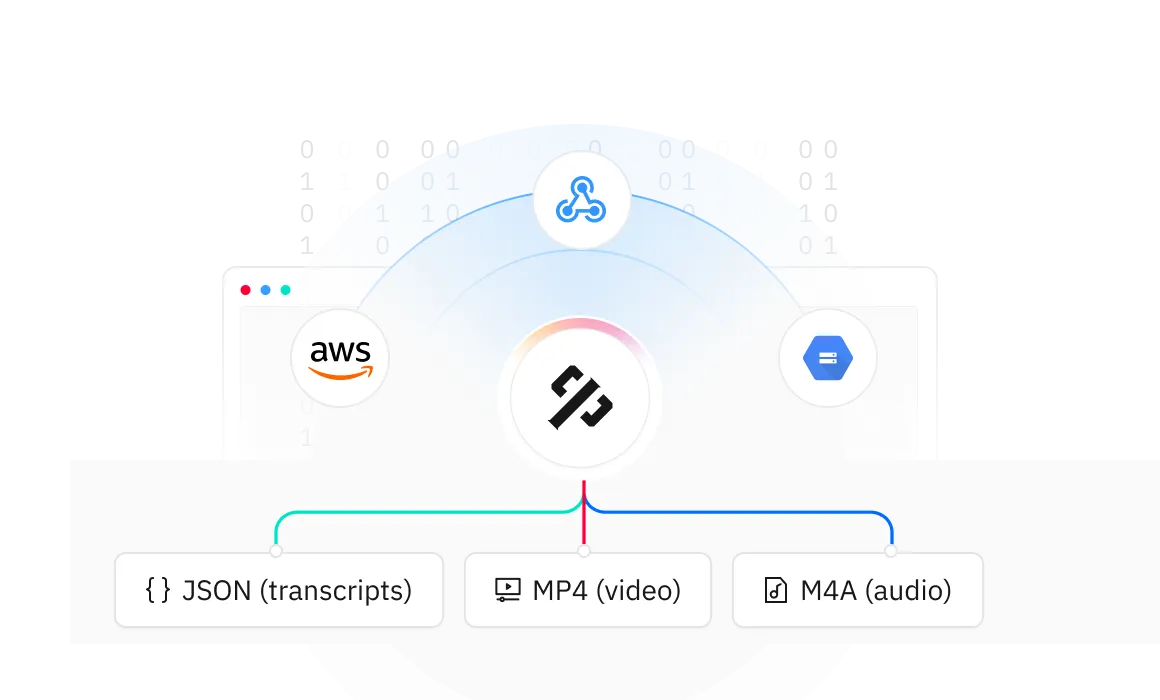
Get your data delivered in your workflow’s format:
Available formats include: JSON (for transcripts and subtitles), MP4 (video), M4A (audio)
Deliver via: Webhook, Google Cloud Storage or AWS S3. Custom integrations are also available
Delivery options: On-demand or scheduled to match your workflow

Unlike generic data, custom datasets boost training efficiency by removing noise while building diversity. This guides models to learn more fundamental patterns, delivering superior generalization and stability in real-world scenarios.
Each dataset contains ethically sourced, AI-ready content backed by verified creator consent. You will receive transcripts, subtitles, video and audio files, along with rich metadata—including upload date, view counts, and channel details.
We offer multiple delivery formats tailored to data type:
Transcripts & Subtitles: .json
Video Files: .mkv or .mp4
Audio Files: .m4a or .mp3
All videos support up to 2K Ultra HD resolution, while audio is delivered in the best available quality from the source—ensuring an authentic and high-fidelity viewing and listening experience.
Datasets can be received via Webhook, Google Cloud Storage or AWS S3 . You may choose on-demand delivery or set a custom schedule.
Absolutely. Our datasets are specially curated for training language models and multimodal AI systems, containing only consent-approved content cleared for AI training.
Yes. We assist in tailoring datasets by content type (video, channel, playlist), upload date, view metrics, and other filters. You may also specify quality preferences and validate outputs with test batches before full delivery.
Yes. You may use YouTube proxies to gather data directly, bypassing blocks, rate limits, and geo-restrictions. However, by choosing our pre-collected high-quality video datasets, you avoid scraping complexities altogether and gain immediate access to ethically sourced, AI-ready content with full creator consent.