Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
Daily video data
YouTube videos covered
High-quality seed URLs
Uptime & 24/7 expert support
No more rate limits, blocks or yt- dlp failures. Just stable, petabyte-scale video data extraction for AI training
Full-spectrum video/audio support
Fully-automated batch downloads
Seamless multi-cloud storage integration with auto-syncing
Transcripts in 100+ languages
Real-time and scalable
Clean, structured outputs (JSON 、CSV 、XLSX)
Comment ID, content, like count, publication date, reply data and more
Real-time & batch processing
Brand Sentiment Monitoring
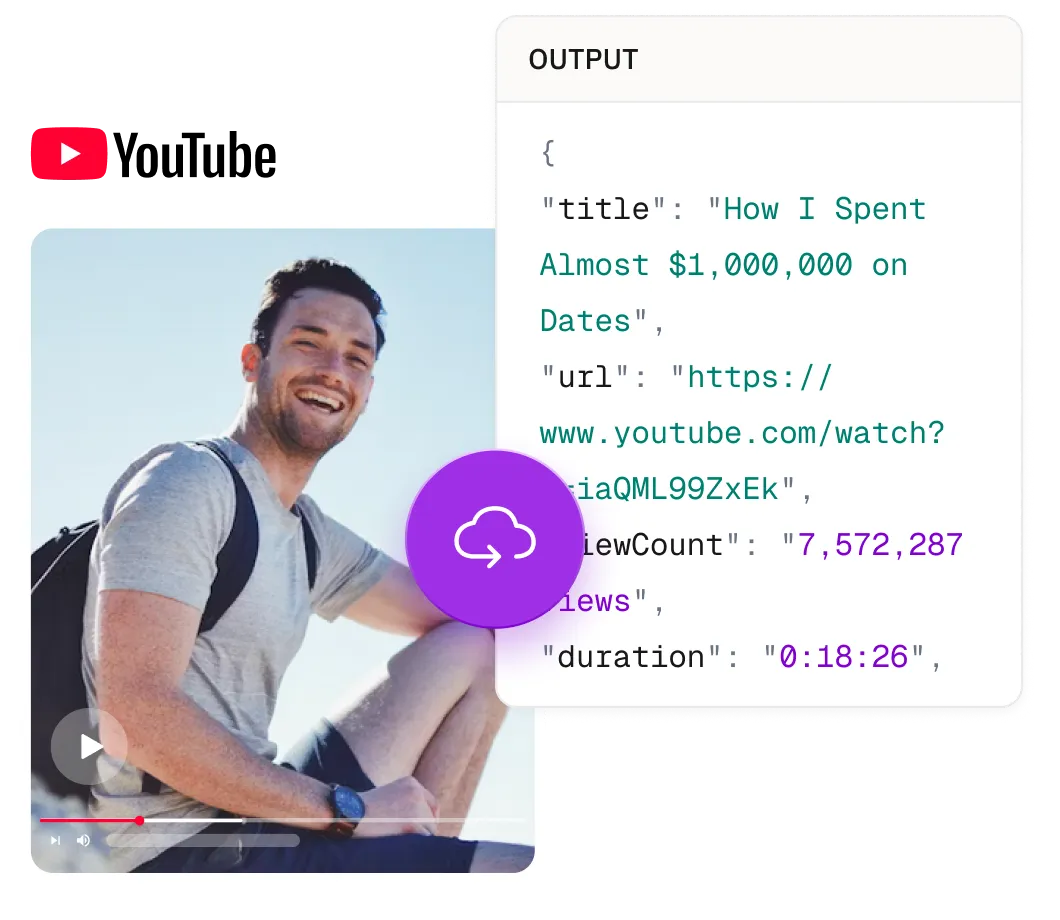
Title, description, view count and publication time and more
Structured, AI-ready data
Real-time, large-scale data
Just a few simple steps to get clear, structured YouTube data.
Parse and access video resources directly using a video ID or URL

Download video/audio content
Retrieve video transcripts
Automatically uploads data to your specified cloud storage
Generates shareable links and provides API access
Provide a list of video IDs, specify the cloud storage destination. We'll seamlessly download them and return status updates. An end-to-end automated solution requiring zero setup.
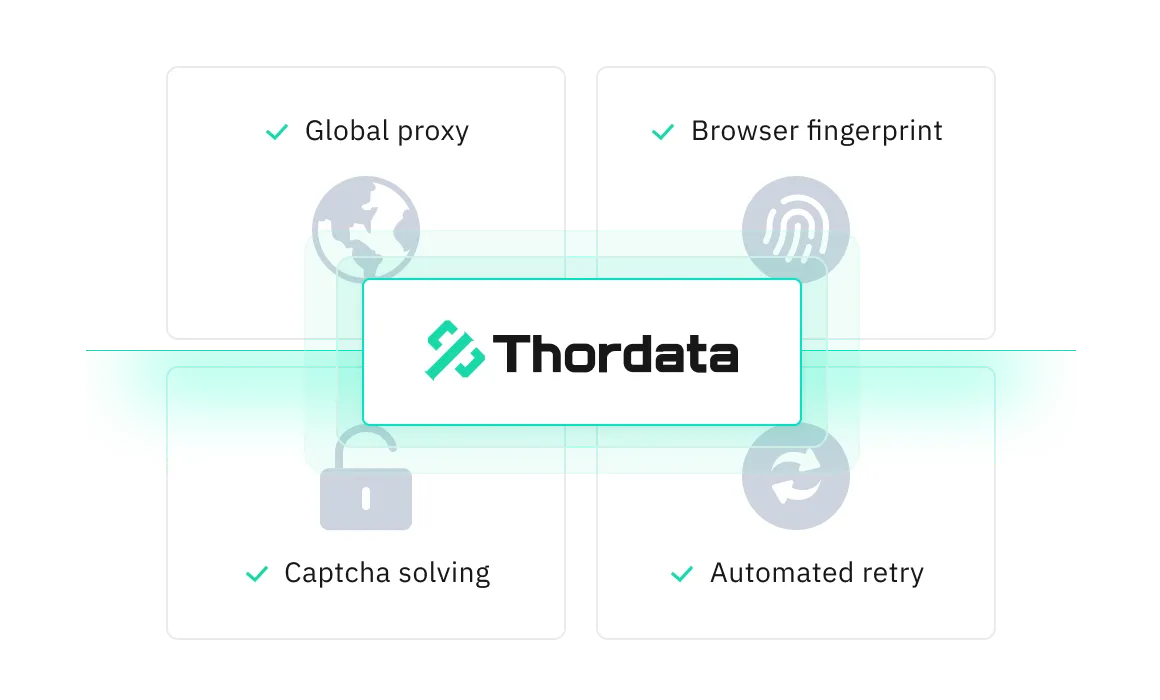
ML-driven proxy selection and rotation using our premium proxy pool from 190 countries.
Unique HTTP headers, JavaScript, and browser fingerprints ensure resilience to dynamic content.
Automatic retries and CAPTCHA bypassing for uninterrupted data retrieval.
Extract data from several pages at the same time with up to 10K URLs per batch.
Receive data via cloud storage such as SFTP or AWS S3, or retrieve results through APIs.
Set your preferred frequency for automated, custom-timed data collection, with results delivered directly to your cloud storage.
Eliminate proxy maintenance and infrastructure hassle. No need to build crawler systems.
Easy to integrate with support for customization.
Receive professional support in case of any questions or issues.
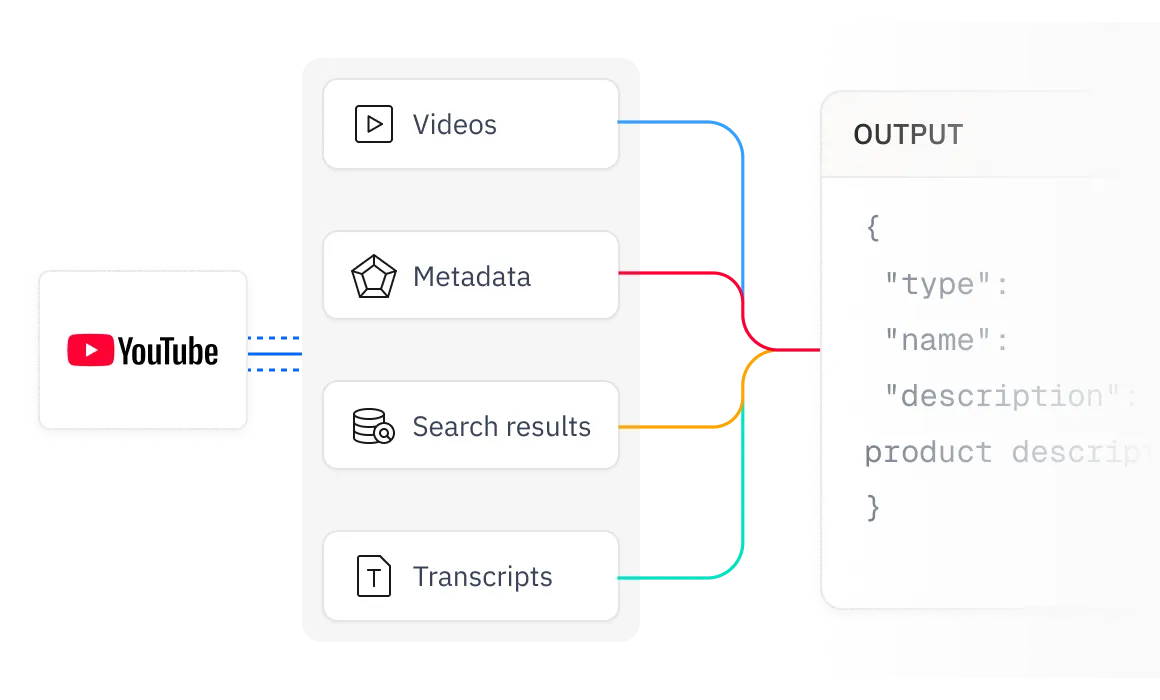
We deliver structured, AI-compatible data, making YouTube videos, transcripts, subtitles, metadata, and search results ready for seamless integration into LLMs, AI models, and analytics workflows.
Reduce data cleaning workloads
Seamless LLM integration
Scalable & automated
Access high-quality video data from real web traffic worldwide
No need to develop or maintain crawlers or browsers
Bypass anti-scraping systems effortlessly
The legality depends on the data extracted and its usage. You must comply with all applicable laws, including copyright. Always consult legal counsel, review Terms of Service, or obtain scraping permissions beforehand.
Yes. Our Web Scraper API integrates with yt-dlp to overcome common extraction barriers—handling blocks, CAPTCHAs, and rate limits automatically. Contact us for approved access based on your use case.
Access structured metadata like title, views, tags, upload time, duration, and channel name—ideal for training and analysis.
Yes. Schedule or batch scraping by keywords, channel/playlist IDs, with fully customizable timing and frequency.
For custom platform requests, contact your dedicated Thordata account manager to discuss options.