Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.
Your First Plan is on Us!
Get 100% of your first residential proxy purchase back as wallet balance, up to $900.


Stop maintaining crawlers and bypassing blocks — receive high-quality, validated structured data directly through ready-to-use or custom datasets.
Access fresh, ready-to-use datasets from 120+ domains
Rigorously cleaned and validated—zero duplicates, zero errors
Daily record refreshes, with monthly dataset updates
Discover continuously updated, ready-to-use structured datasets. Browse with ease and access flexibly—find the perfect match for your project.
120+ domains
190+ datasets
7.7K+ data sample downloads
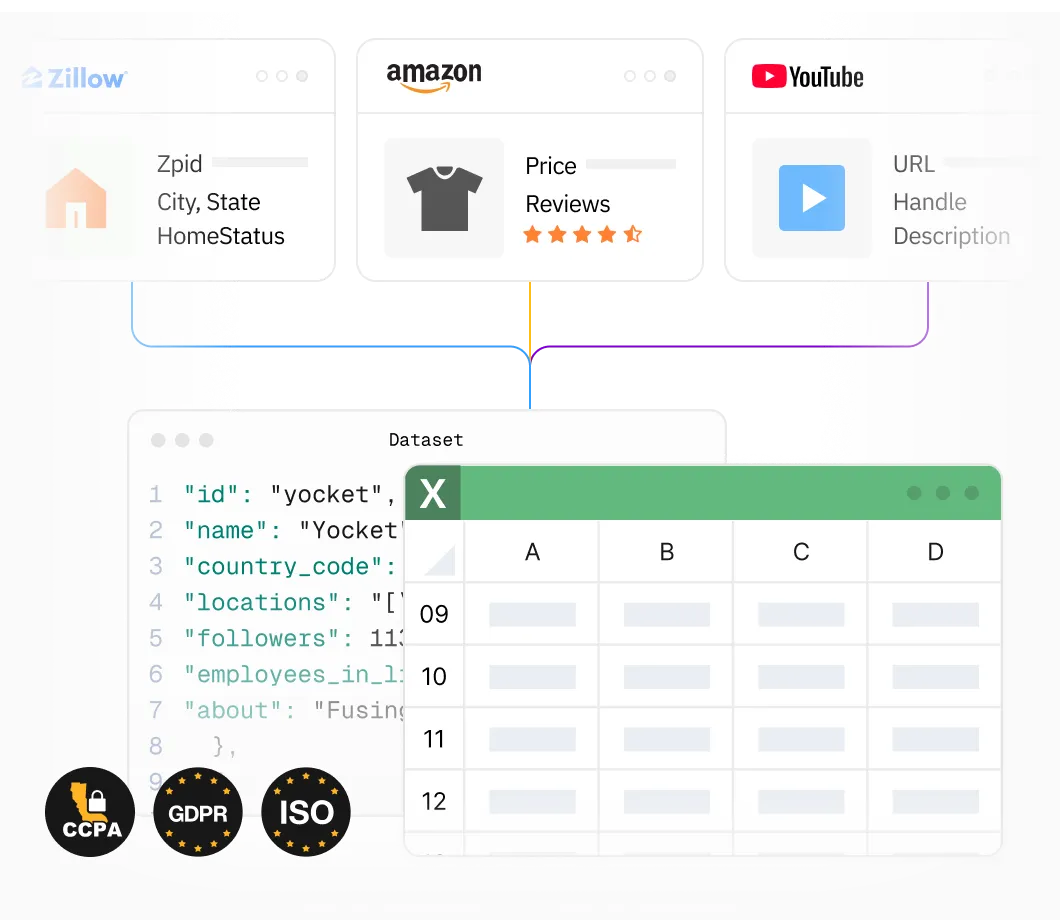
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
URL, Post url, Post id, Post date created, Date created, Comment text, Num likes, Num replies, and more.
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
URL, Linkedin id, Name, About, Position, Optional jobs, Country code, Experience, and more.
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
URL dataset to access URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
Title, Seller name, Brand, Description, Initial price, Final price, Final price high, Currency, and more.
URL, Product id, Title, Final price, Initial price, Currency, Rating, Reviews count, and more.
Seller id, URL, Seller name, Description, Detailed info, Stars, Feedbacks, Return policy, and more.
Asin, URL, Name, Sponsored, Initial price, Final price, Currency, Sold, and more.
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
URL, Zpid, Date, Event, Posting is rental, Price, Price change rate, Price per squarefoot, and more.
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Comment id, Comment text, Likes, Replies, Username, Username md5, User channel, Date, and more.
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Explore the hospitality landscape with detailed property listings from Booking.com
URL, Post id, Post url, Comment id, User name, User id, User url, Date created, and more.
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
URL, Review id, Reviewer name, Review date, Review rating, Review, Found helpful, App url, and more.
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
Seller id, URL, Catalog seller id, Seller name, Seller display name, Seller email, Seller phone, Seller about us, and more.
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Clear field definitions with structural documentation and downloadable data samples. This allows you to thoroughly evaluate data quality, formatting, and relevance before making a commitment.
Ready-to-use datasets—no collection or cleaning required, saving time and boosting efficiency.
Standardized data schema
Fresh, clean, and parsed data
Supports JSON, CSV and other mainstream data formats for easy integration
•Enrich speech, vision, or multimodal datasets
•Train vertical AI models or fine-tuning LLMs
Precise access to public web data, deeply aligned with your domain-specific business needs.
Customizable data sources, collection rules, format, and schedule
Flexible and scalable solutions to accommodate business growth
Sample data validation ensures requirements are met
•Pre-training initial models
•Domain-specific analysis and deep insights
We maintain the most competitive market pricing — delivering richer data volume and broader dimensions within your budget to maximize business growth.
Combine two or more datasets and unlock exclusive bundle pricing—maximizing breadth and ROI in one purchase.
Scale smarter with tiered discounts on large-volume datasets and subscription plans—more data, less cost.
Integrate multiple sources seamlessly with pre-merged, analysis-ready datasets—clean, unified, and built to save you time.
 Cleaned Verified Compliant Ready-to-use Structured Daily Updates
Cleaned Verified Compliant Ready-to-use Structured Daily Updates
No coding or maintenance
Highly scalable
Periodic data delivery
Supports billions of records
NDJSON, JSON, CSV formats
Delivers only new or updated data
24/7 technical support
Customizable solutions
Pre-processed with consistent schemas—optimized for AI training and inference.
Ready-to-use snippets in Python, Node.js, cURL, PHP, Go, Java, and Ruby—seamlessly fit into AI workflows.
24/7 expert support for ChatGPT, Claude and other LLMs—from integration to optimization.
We manage the entire public web data extraction process, delivering the finalized dataset to you.
Build custom datasets using AI-powered tools—no coding required, pay only for what you need.
Choose flexible subscription plans supporting full updates, incremental additions, or targeted data refreshes.
Filter and retrieve data directly within your applications—streamlining workflows with seamless integration.
Export data via S3, API, Webhook, and more—effortlessly connecting to your infrastructure.
Receive data in JSON or CSV formats—adapting to diverse data processing needs.
Monitor data fill rates and statistical metrics in real-time—ensuring compliance with your quality standards.
Access high-quality datasets to train and refine AI and ML models—enabling personalized content, accurate image recognition, and continuous LLM innovation.
Text, Images, Videos, 3D Models, and more.
Thordata Dataset Marketplace are validated collections of high-quality datasets covering various topics, sourced from various reliable and diverse public online data sources. These datasets are meticulously gathered, cleaned, and structured to provide valuable business insights.
Thordata offers diverse datasets spanning industries such as AI and LLMs, e-commerce, finance, travel, social media, and more. These datasets encompass various data types, including text, images, videos, and structured data, providing comprehensive coverage for different analytical needs.
Yes, we get that different projects have unique requirements. This is why we offer customization options for datasets, allowing users to tailor the data to specific parameters such as timeframes, geographic regions, or specific data fields. This ensures that the datasets you receive are perfectly suited to your needs.
Thordata prioritizes ethical data-sourcing practices. They adhere to strict ethical guidelines and comply with all relevant regulations to ensure that the data provided is obtained ethically and legally. Additionally, Thordata is committed to maintaining the privacy and security of data subjects and users.
Yes. Each dataset undergoes rigorous quality assurance processes to ensure accuracy, reliability, and relevance. Additionally, we continuously update and refresh our datasets to reflect the latest information, ensuring that users always have access to the most current data.
Common use cases include machine learning and AI model training, product enrichment, market research, trend analysis, sentiment analysis.
Data formats include JSON, CSV.
Not a problem. Before proceeding to checkout, you will be able to define the time range of the data freshness you would like to get.
You can choose between instantly available datasets, with data dating back from a few days to a couple of months, or freshly collected data.
Yes. You can subscribe to any dataset and receive fresh data directly to your storage on a daily, weekly, monthly, quarterly or yearly basis.