您的首个套餐免费!
首次住宅代理消费金额将全额返还至您的钱包余额,最高可达900美元。
您的首个套餐免费!
首次住宅代理消费金额将全额返还至您的钱包余额,最高可达900美元。
每日可新增视频数据
Youtube 全视频覆盖
高质量原始种子
运行时间和全天候专家支持
无需担心请求限制、访问拦截或 yt-dlp 故障,我们提供稳定高效的 PB 级视频数据采集服务,专为 AI 训练定制
全格式视频/音频
全自动批量下载
跨平台云存储,数据自动同步
覆盖 100+语言的转录文本
实时且大规模的数据
结构化、适用于 AI 训练的数据(JSON 、CSV 、XLSX)
评论、内容、点赞数、发布日期、回复等数据
实时与批量处理
品牌舆情监测
视频标题、频道、观看量、标签和互动等数据
全自动化批量处理
可直接用于 AI 训练
仅需简单的步骤即可获得清晰、结构化的YouTube数据。
通过视频ID或URL直接解析并获取视频资源

下载视频/音频内容
检索视频转录文本
数据自动上传至指定云存储
生成访问链接并提供 API 接口
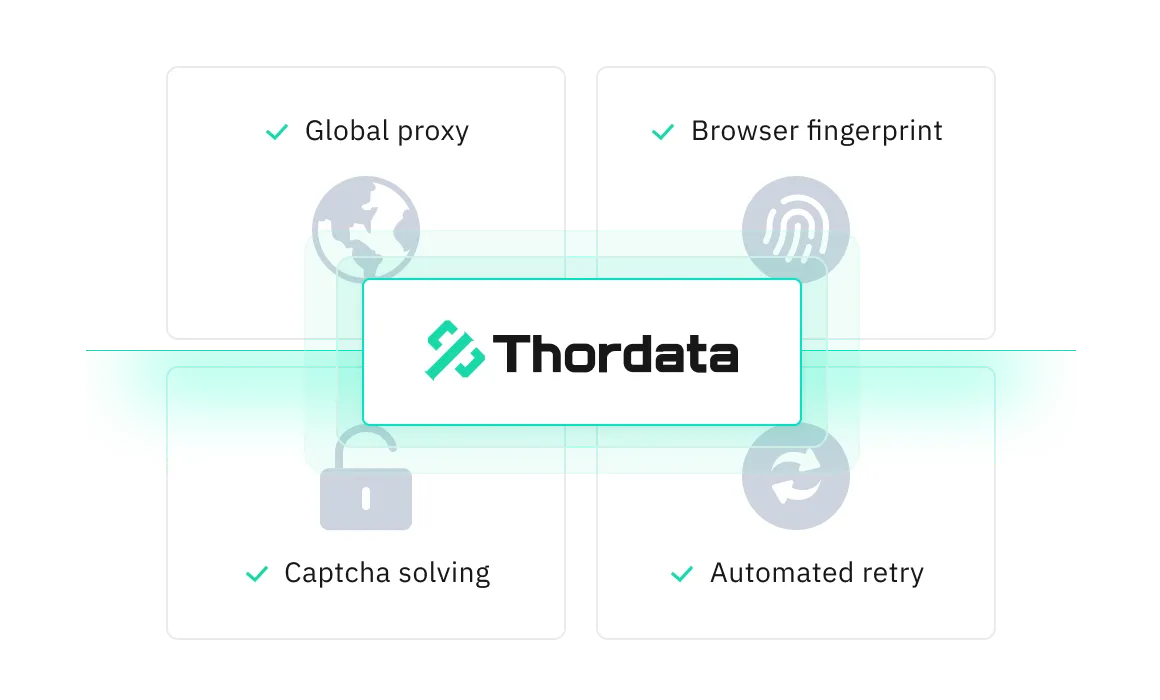
依托覆盖 190 个国家的优质代理池,通过机器学习智能选择并轮换代理 IP
模拟真实用户的 HTTP 头、JavaScript 及浏览器指纹,高效适应动态内容。
具备自动重试与验证码绕过功能,保障数据抓取不间断。
支持同时从多个页面抓取数据,每批最多可处理 10000 个 URL
支持将数据直接传输至 Amazon、GCS、阿里云 OSS 等 S3 兼容存储,也可通过API 获取结果。
可灵活设置任务频率,按自定义时间或规则自动抓取,并将数据推送至云存储。
彻底告别代理维护与基础设施解锁,无需构建爬虫系统。
轻松集成,支持大量请求,可按需定制。
全天候专业支持,及时解答疑问、解决问题。
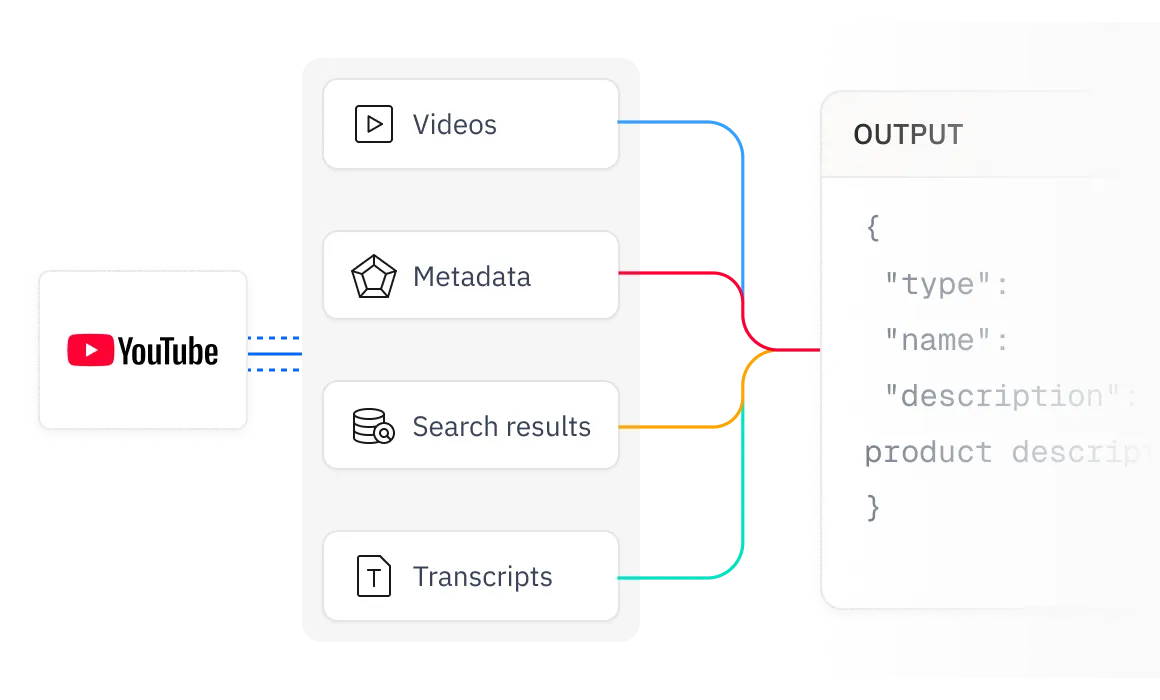
我们提供结构化、AI兼容的数据,使YouTube视频、文字记录、字幕、元数据和搜索结果能够无缝集成到LLM、AI模型和分析工作流中。
减少数据清洗工作量
无缝LLM集成
可扩展且自动化
从全球范围获取真实 Web 访问的高质量视频数据
无需开发与维护爬虫和浏览器
绕过反爬系统
抓取 YouTube 数据的合法性主要取决于您提取的具体数据以及使用方式。必须遵守所有相关法律法规,包括著作权法。在进行任何网络抓取活动之前,请咨询法律顾问,查阅相应网站的服务条款或获取网络抓取许可。
是的,Thordata的网页抓取API可与yt-dlp集成,以解决常见的数据提取问题,该 API 可作为智能代理层,通过自动处理访问拦截、验证码和速率限制等问题来增强 yt-dlp 的功能。请联系我们的专家团队,说明您的具体使用场景,获取经审批的 yt-dlp 集成使用权限。
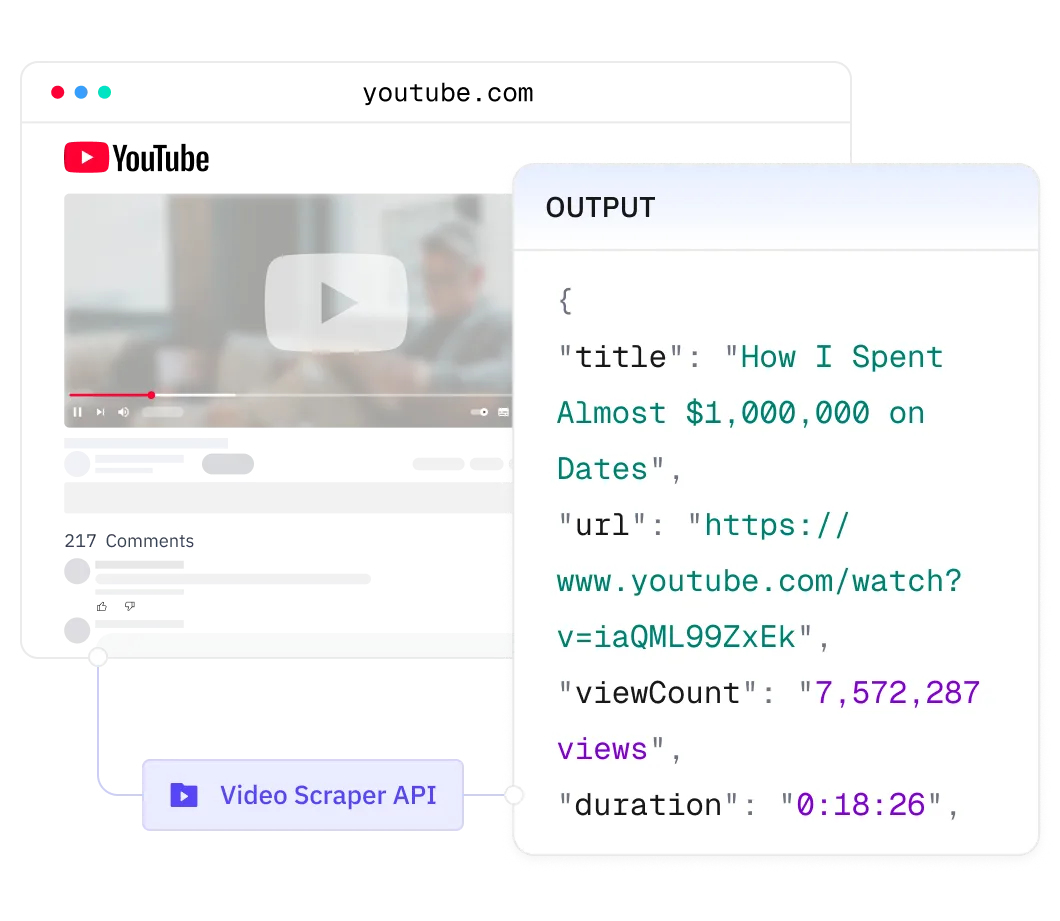
您可以获取源视频的详细元数据,包括标题、观看次数、标签、发布时间、长度、频道名称等。 所有数据均为结构化格式,非常适用于训练和分析
支持批量抓取与定时任务,可灵活设置搜索关键词、频道 ID 或播放列表等来源,自定义抓取时间。实现灵活频率抓取
如果您需要从指定平台抓取数据,请联系 Thordata 为您提供的专属客户经理,共同讨论您的需求