Gói Đầu Tiên Của Bạn Miễn Phí!
Trả lại 100% giá trị mua proxy dân cư lần đầu tiên vào số dư ví, tối đa 900 đô la.
Gói Đầu Tiên Của Bạn Miễn Phí!
Trả lại 100% giá trị mua proxy dân cư lần đầu tiên vào số dư ví, tối đa 900 đô la.


Mở khóa dữ liệu thời gian thực của Twitter qua API Scraping Twitter, bao gồm URL, hashtags, hình ảnh, video, tweets, retweets, chuỗi hội thoại, người theo dõi/đang theo dõi, địa điểm và nhiều nội dung khác.
Không cần xây dựng máy chủ hoặc bảo trì mã code
Chỉ thanh toán cho các kết quả thành công
Yêu cầu hàng loạt — lên đến 10K URL
Giao dữ liệu có cấu trúc: JSON, CSV, XLSX
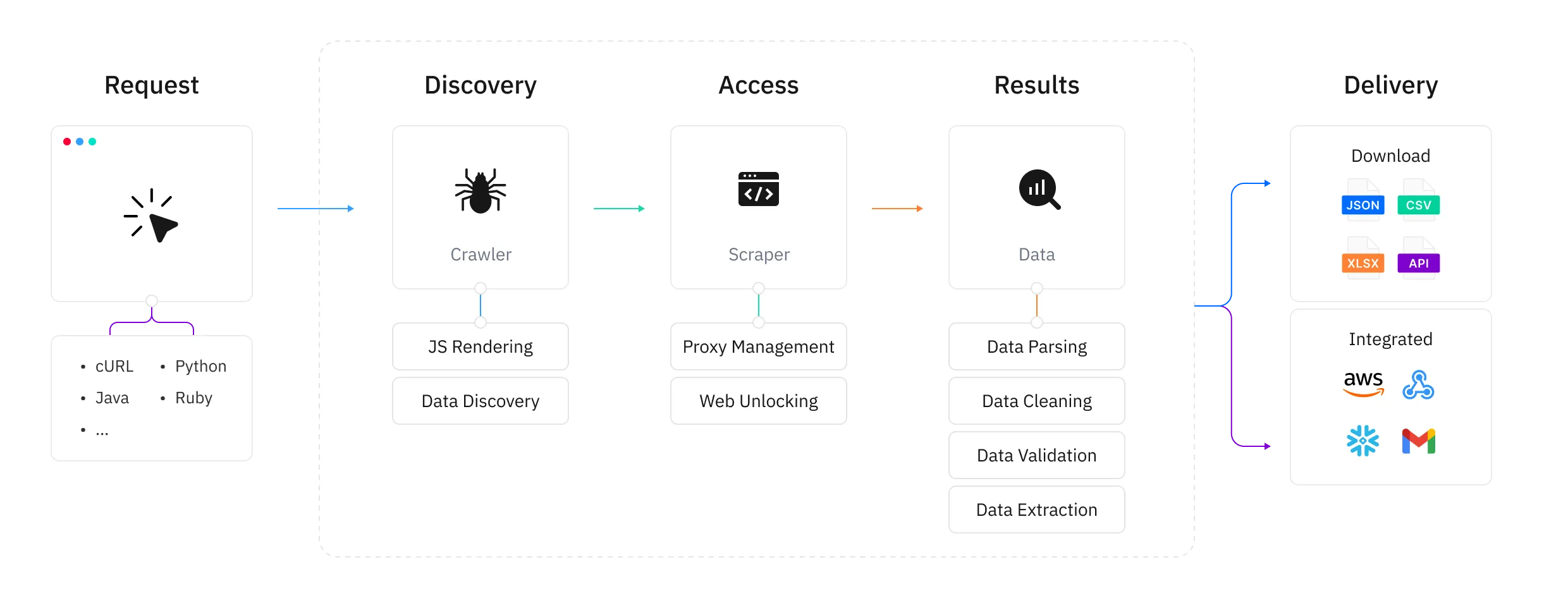
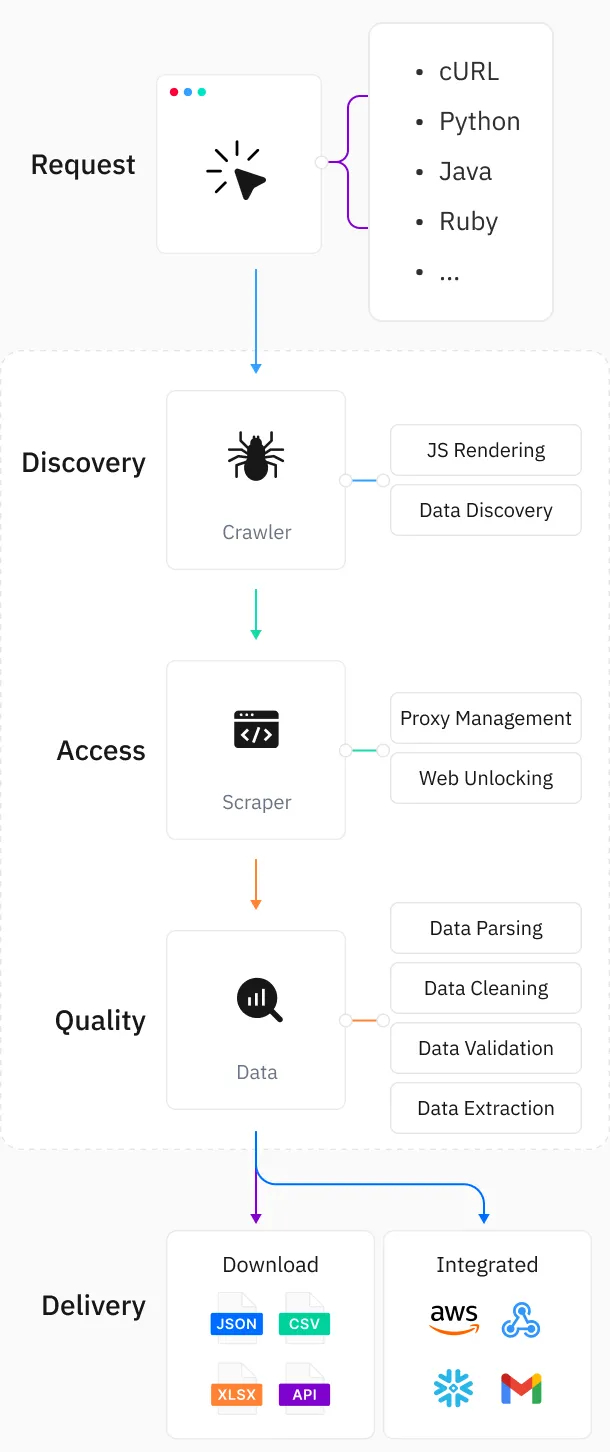
Xây Dựng Yêu Cầu Với API Của Chúng Tôi
Thu thập dữ liệu quy mô lớn qua API,hỗ trợ 9 ngôn ngữ lập trình.Tự Động Hóa Chức Năng
Tạo bộ lập lịch thu thập tùy chỉnh theo nhu cầu cụ thể của bạn.Giao Dữ Liệu
Tự động giao dữ liệu đã thu thập đến dịch vụ lưu trữ đám mây bạn chỉ định.Công Cụ Thu Thập Dữ Liệu Trên Bảng Điều Khiển
Toàn bộ quy trình được quản lý trong bảng điều khiển [Bảng điều khiển - Trình thu thập dữ liệu web] của chúng tôi.Linh Hoạt & Thân Thiện
Cấu hình mục tiêu và bắt đầu thu thập ngay lập tức,với tác vụ được lập lịch để thu thập tự động.Truy Xuất Kết Quả
Tải xuống tệp đầu ra trực tiếp từ [Bảng điều khiển - Tác vụ].Không cần phát triển hoặc duy trì cơ sở hạ tầng — chỉ cần tập trung vào việc trích xuất dữ liệu web quy mô lớn. API Web Scraper đảm bảo khả năng mở rộng và độ tin cậy.
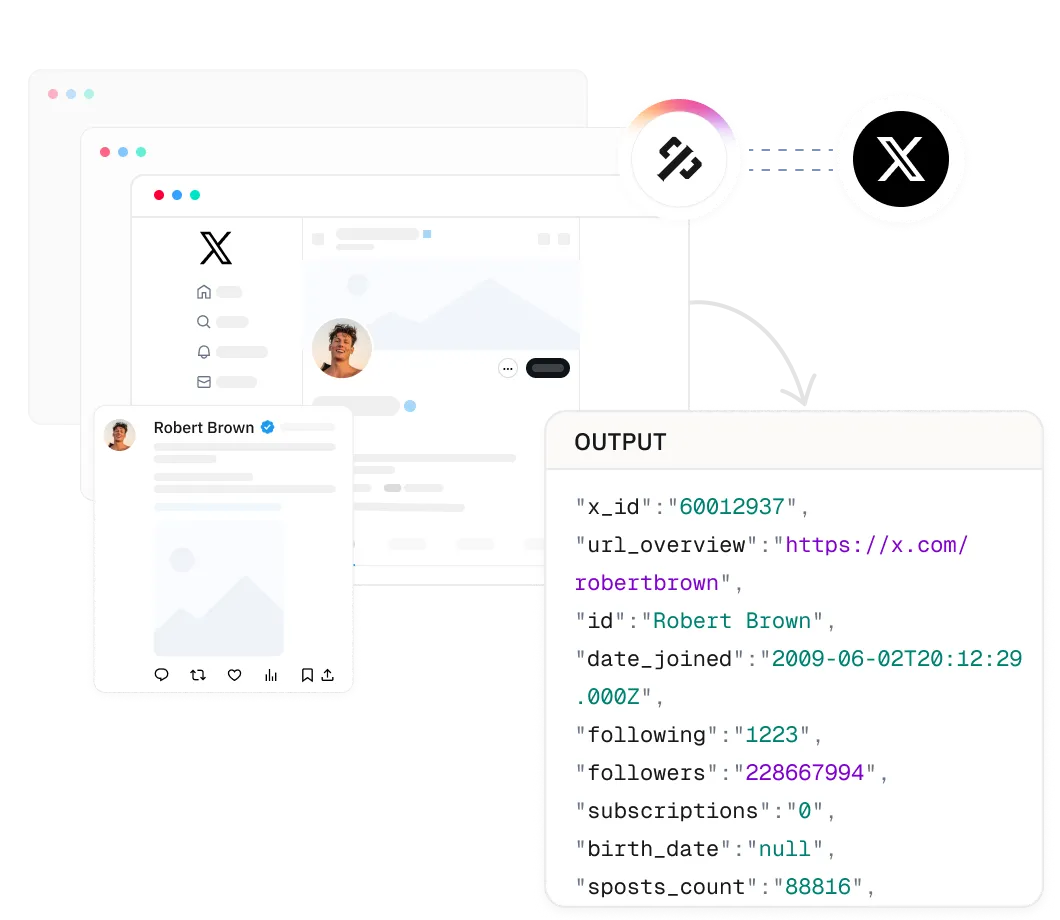
Trích xuất dữ liệu đầy đủ của người dùng, bao gồm ID duy nhất, liên kết cá nhân, biệt danh, tên người dùng, tiểu sử, trạng thái xác minh, URL ảnh hồ sơ, liên kết bên ngoài, ngày tạo tài khoản, số lượng người theo dõi/đang theo dõi, số lượng đăng ký, địa điểm, sinh nhật, số lượng tweet, tweet đã đăng và tài khoản liên quan.
Phương Pháp Scraping:
Lấy dữ liệu chi tiết của tweet, bao gồm ID tweet, thông tin người đăng, ngày đăng, nội dung đầy đủ, phương tiện đính kèm (hình ảnh, video, tweet trích dẫn), chỉ số tương tác (trả lời, retweet, thích, lượt xem), cũng như liên kết bên ngoài và hashtag được bao gồm.
Phương Pháp Scraping:
Trích xuất bài đăng từ một người dùng cụ thể qua tên người dùng. Trả về URL tweet, ID, ngày, nội dung đầy đủ, phương tiện đính kèm (hình ảnh, video), chỉ số tương tác, hashtag, NGOÀI RA còn có thông tin sâu về người đăng như số lượng người theo dõi, tiểu sử, số lượng tweet và ảnh hồ sơ.
Phương Pháp Scraping:
Liên hệ với chuyên gia kỹ thuật của chúng tôi để nhận giải pháp scraping dữ liệu tùy chỉnh.
Lấy thông tin thuộc tính của Twitter (X) trong vài giây với một cuộc gọi API đơn giản.
Luân chuyển IP thông minh
Nhận diện CAPTCHA tự động
Tiêu đề HTTP
Phân tích cú pháp trang web tự động
Hỗ trợ tùy chỉnh

Quản Lý Tài Khoản Chuyên Trách
Tệp Cấu Trúc Tùy Chỉnh
Nền Tảng Thu Thập Dữ Liệu Tùy Chỉnh
Lịch Giao Hàng Linh Hoạt
Trường Dữ Liệu Tùy Chỉnh
Gói Dữ Liệu Tùy Chỉnh
Tối ưu hóa quy trình làm việc, tăng cường tự động hóa và đạt được mức hiệu suất mới.
Lựa chọn và luân chuyển proxy được điều khiển bằng ML, sử dụng kho proxy cao cấp của chúng tôi từ 190 quốc gia.
Tiêu đề HTTP, JavaScript và dấu vết trình duyệt độc đáo đảm bảo khả năng chống chịu với nội dung động.
Thử lại tự động và vượt qua CAPTCHA để thu thập dữ liệu không bị gián đoạn.
Trích xuất dữ liệu từ nhiều trang cùng một lúc với tối đa 10K URL cho mỗi yêu cầu.
Chuyển dữ liệu đến Amazon S3, Snowflake, Webhooks hoặc các kho lưu trữ tương thích khác, hoặc truy cập kết quả thông qua API.
Thiết lập tần suất ưa thích của bạn để thu thập dữ liệu tự động theo thời gian tùy chỉnh, với kết quả được giao trực tiếp đến kho lưu trữ đám mây của bạn.
Có được sự kiểm soát và linh hoạt tối đa mà không cần duy trì cơ sở hạ tầng proxy và gỡ chặn.
Tích hợp dễ dàng, hỗ trợ số lượng yêu cầu lớn và có thể tùy chỉnh hoàn toàn.
Nhận hỗ trợ chuyên nghiệp trong trường hợp có bất kỳ câu hỏi hoặc sự cố nào.
Lợi thế lớn nhất của công cụ này là tốc độ đáng kinh ngạc và độ tin cậy cực cao. Trong lĩnh vực tình báo thị trường, thời điểm là tất cả. Trong khi các đối thủ cạnh tranh của chúng tôi vẫn đang xây dựng công cụ scraping, chúng tôi đã bắt đầu phân tích dữ liệu. Nó đã thay đổi nền tảng luồng làm việc của chúng tôi, cho phép chúng tôi theo dõi nhận định thương hiệu và xu hướng mới nổi gần thời gian thực, điều này trực tiếp cung cấp cơ sở cho báo cáo chiến lược dành cho khách hàng.
Sarah Chen
Giám Đốc Nghiên Cứu Thị TrườngĐối với tôi, sự giúp đỡ mà nó mang lại tập trung vào độ sâu và linh hoạt của dữ liệu. Tôi cần dữ liệu toàn diện về tương tác của đối tượng khán giả của đối thủ cạnh tranh — không chỉ các bài đăng của họ, mà cả bức tranh đầy đủ về lượt thích, chia sẻ và phản hồi. Công cụ này cung cấp những thứ này tức thời qua URL hoặc tên người dùng. Giao diện đơn giản có nghĩa là tôi có thể thực hiện thu thập dữ liệu phức tạp trong vài phút, không cần mất vài giờ, để tôi có thêm thời gian投入 vào phân tích thực tế và lập kế hoạch chiến lược.
David Rodriguez
Phân Tích Viên Chiến Lược Cạnh TranhĐiểm mạnh lớn nhất của nó là sự kết hợp giữa sức mạnh tuyệt đối và tính đơn giản. Tôi không phải là nhà phát triển, nhưng không cần phải là. Tôi có thể bắt đầu sử dụng không cần bất kỳ đào tạo nào. Tôi có thể nhanh chóng nhận được dữ liệu sạch sẽ và có cấu trúc về nhân khẩu học người dùng và hiệu suất nội dung. Điều này giúp tôi xây dựng nhân vật người dùng dựa trên dữ liệu và hiểu rõ các lĩnh vực thị trường với mức độ tự tin mà chúng tôi chưa từng có trước đây.
Emily Watson
Nhà Tư Vấn Chiến Lược Thương HiệuNgoài chức năng scraping nhanh chóng, hỗ trợ khách hàng xuất sắc cũng là một lợi thế lớn. Chúng tôi từng có yêu cầu cụ thể về định dạng dữ liệu, và đội ngũ đã giải quyết nó trong vòng một giờ. Hiệu quả như vậy thật khó tin. Công cụ này giúp cả đội ngũ của chúng tôi khi trở thành một "người giúp việc" đáng tin cậy. Chúng tôi đã thiết lập giám sát cho từ khóa chiến dịch và người có ảnh hưởng trong ngành, và nó hoạt động hoàn hảo ở chế độ nền, cung cấp dữ liệu liên tục cho bảng điều khiển insight hàng ngày của chúng tôi.
James Kim
Giám Đốc Insight SốLà một nhà tư vấn độc lập, tôi cần những công cụ kinh tế hiệu quả và không tạo thêm công việc. Lợi ích lớn nhất của công cụ scraping này đối với tôi là hiệu suất. Nó rất nhanh chóng và không có rào cản học tập, nghĩa là tôi có thể nhận thêm khách hàng mà không cần tăng chi phí kỹ thuật. Nó giúp tôi cung cấp cho khách hàng những câu trả lời vững chắc, dựa trên dữ liệu về "thị trường đang diễn ra gì?" nhanh hơn bao giờ hết — và đây chính là giá trị cốt lõi của tôi.
Linda Patterson
Nhà Nghiên Cứu Thị Trường Độc LậpLợi thế lớn nhất của công cụ này là tốc độ đáng kinh ngạc và độ tin cậy cực cao. Trong lĩnh vực tình báo thị trường, thời điểm là tất cả. Trong khi các đối thủ cạnh tranh của chúng tôi vẫn đang xây dựng công cụ scraping, chúng tôi đã bắt đầu phân tích dữ liệu. Nó đã thay đổi nền tảng luồng làm việc của chúng tôi, cho phép chúng tôi theo dõi nhận định thương hiệu và xu hướng mới nổi gần thời gian thực, điều này trực tiếp cung cấp cơ sở cho báo cáo chiến lược dành cho khách hàng.
Sarah Chen
Giám Đốc Nghiên Cứu Thị TrườngĐối với tôi, sự giúp đỡ mà nó mang lại tập trung vào độ sâu và linh hoạt của dữ liệu. Tôi cần dữ liệu toàn diện về tương tác của đối tượng khán giả của đối thủ cạnh tranh — không chỉ các bài đăng của họ, mà cả bức tranh đầy đủ về lượt thích, chia sẻ và phản hồi. Công cụ này cung cấp những thứ này tức thời qua URL hoặc tên người dùng. Giao diện đơn giản có nghĩa là tôi có thể thực hiện thu thập dữ liệu phức tạp trong vài phút, không cần mất vài giờ, để tôi có thêm thời gian投入 vào phân tích thực tế và lập kế hoạch chiến lược.
David Rodriguez
Phân Tích Viên Chiến Lược Cạnh TranhĐiểm mạnh lớn nhất của nó là sự kết hợp giữa sức mạnh tuyệt đối và tính đơn giản. Tôi không phải là nhà phát triển, nhưng không cần phải là. Tôi có thể bắt đầu sử dụng không cần bất kỳ đào tạo nào. Tôi có thể nhanh chóng nhận được dữ liệu sạch sẽ và có cấu trúc về nhân khẩu học người dùng và hiệu suất nội dung. Điều này giúp tôi xây dựng nhân vật người dùng dựa trên dữ liệu và hiểu rõ các lĩnh vực thị trường với mức độ tự tin mà chúng tôi chưa từng có trước đây.
Emily Watson
Nhà Tư Vấn Chiến Lược Thương HiệuNgoài chức năng scraping nhanh chóng, hỗ trợ khách hàng xuất sắc cũng là một lợi thế lớn. Chúng tôi từng có yêu cầu cụ thể về định dạng dữ liệu, và đội ngũ đã giải quyết nó trong vòng một giờ. Hiệu quả như vậy thật khó tin. Công cụ này giúp cả đội ngũ của chúng tôi khi trở thành một "người giúp việc" đáng tin cậy. Chúng tôi đã thiết lập giám sát cho từ khóa chiến dịch và người có ảnh hưởng trong ngành, và nó hoạt động hoàn hảo ở chế độ nền, cung cấp dữ liệu liên tục cho bảng điều khiển insight hàng ngày của chúng tôi.
James Kim
Giám Đốc Insight SốLà một nhà tư vấn độc lập, tôi cần những công cụ kinh tế hiệu quả và không tạo thêm công việc. Lợi ích lớn nhất của công cụ scraping này đối với tôi là hiệu suất. Nó rất nhanh chóng và không có rào cản học tập, nghĩa là tôi có thể nhận thêm khách hàng mà không cần tăng chi phí kỹ thuật. Nó giúp tôi cung cấp cho khách hàng những câu trả lời vững chắc, dựa trên dữ liệu về "thị trường đang diễn ra gì?" nhanh hơn bao giờ hết — và đây chính là giá trị cốt lõi của tôi.
Linda Patterson
Nhà Nghiên Cứu Thị Trường Độc LậpLiên Hệ Chuyên Gia Kỹ Thuật Để Thảo Luận Về Nhu Cầu Thu Thập Dữ Liệu Của Bạn.
Đó là một công cụ chuyên dụng cho phép bạn trích xuất dữ liệu công khai từ nền tảng Twitter(X) qua phương thức lập trình, bao gồm hồ sơ người dùng, nội dung bài đăng và chỉ số tương tác, không cần tự xây dựng và duy trì cơ sở hạ tầng scraping của riêng mình.
Bạn có thể trích xuất dữ liệu dễ dàng bằng cách cung cấp các mục tiêu cụ thể như URL hồ sơ người dùng, URL tweet hoặc tên người dùng. API xử lý tất cả độ phức tạp kỹ thuật, cho phép bạn lấy dữ liệu có cấu trúc trong vài phút chỉ với vài yêu cầu đơn giản.
API của chúng tôi được thiết kế chỉ truy cập dữ liệu công khai, tuân thủ các điều khoản dịch vụ của Twitter. Chúng tôi mạnh mẽ khuyên người dùng tôn trọng luật bảo mật dữ liệu và triển khai các phương pháp xử lý dữ liệu có trách nhiệm cho các trường hợp sử dụng cụ thể của họ.
API trả về kết quả trong vài phút, không cần mất vài giờ. Như một khách hàng đã nhận xét: "Trong khi các đối thủ cạnh tranh của chúng tôi vẫn đang xây dựng công cụ scraping, chúng tôi đã bắt đầu phân tích dữ liệu." Công cụ được tối ưu hóa cho việc giao dữ liệu tốc độ cao trong khi duy trì độ tin cậy.
API cung cấp đầu ra chuẩn JSON/CSV có thể tích hợp dễ dàng với hầu hết các nền tảng phân tích dữ liệu, công cụ BI và ứng dụng tùy chỉnh. Hỗ trợ Webhook và tài liệu toàn diện đảm bảo việc tích hợp trơn tru vào luồng làm việc hiện có của bạn.
Như người dùng đã xác nhận: "Sự kết hợp giữa sức mạnh tuyệt đối và tính đơn giản" có nghĩa là bạn nhận được khả năng trích xuất dữ liệu cấp doanh nghiệp mà không cần chi phí phát triển. Điều này loại bỏ hàng tháng xây dựng, kiểm thử và duy trì công cụ scraping, đồng thời mang lại kết quả nhanh hơn, đáng tin cậy hơn.
Các API chuyên nghiệp tự động xử lý giới hạn tốc độ, thay đổi cấu trúc dữ liệu và phát hiện chống bot. Điều này đảm bảo chất lượng và độ tin cậy dữ liệu nhất quán mà các phương pháp thủ công hoặc công cụ scraping cơ bản không thể duy trì lâu dài.
Có, API hỗ trợ tự động hóa hoàn toàn cho các tác vụ giám sát liên tục. Bạn có thể thiết lập theo dõi liên tục các tài khoản, từ khóa hoặc hashtag cụ thể, với dữ liệu trôi chảy trực tiếp vào bảng điều khiển và hệ thống báo cáo của bạn.
Chúng tôi thường cung cấp các tùy chọn dùng thử cho người dùng mới để đánh giá khả năng của API. Vui lòng liên hệ với đội ngũ bán hàng của chúng tôi để thảo luận về nhu cầu cụ thể và các tùy chọn thử nghiệm khả dụng.