Gói Đầu Tiên Của Bạn Miễn Phí!
Trả lại 100% giá trị mua proxy dân cư lần đầu tiên vào số dư ví, tối đa 900 đô la.
Gói Đầu Tiên Của Bạn Miễn Phí!
Trả lại 100% giá trị mua proxy dân cư lần đầu tiên vào số dư ví, tối đa 900 đô la.
Dữ liệu video hàng ngày
Video YouTube được bao phủ
URL hạt giống chất lượng cao
Thời gian hoạt động & hỗ trợ chuyên gia 24/7
Không còn giới hạn tốc độ, chặn hoặc lỗi yt-dlp. Chỉ cần trích xuất dữ liệu video ổn định ở quy mô petabyte cho đào tạo AI
Hỗ trợ video/âm thanh toàn phổ
Tải xuống hàng loạt tự động hoàn toàn
Tích hợp lưu trữ đám mây liền mạch với đồng bộ hóa tự động
Bản ghi âm bằng 100+ ngôn ngữ
Thời gian thực và có thể mở rộng
Đầu ra có cấu trúc sạch (JSON 、CSV 、XLSX)
ID bình luận, nội dung, số lượt thích, ngày xuất bản, dữ liệu trả lời và hơn thế nữa
Xử lý thời gian thực & hàng loạt
Giám sát Cảm xúc Thương hiệu
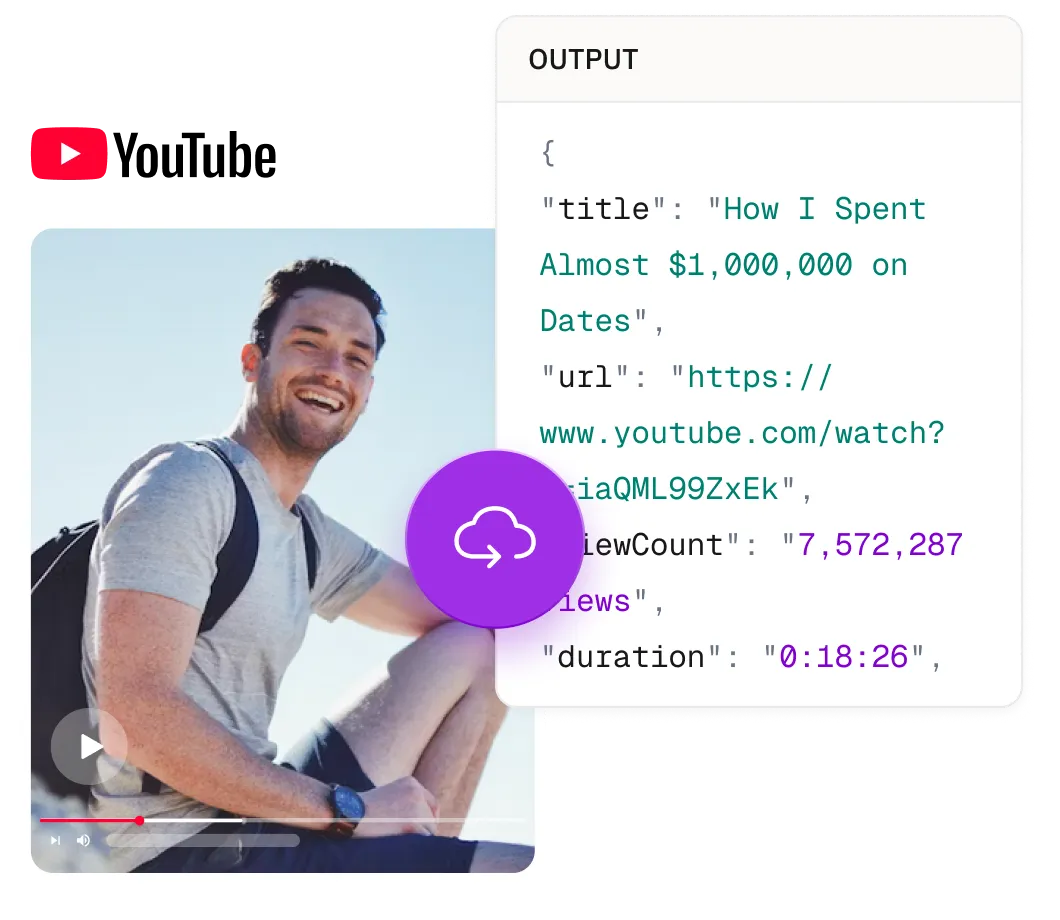
Tiêu đề, mô tả, số lượt xem, thời gian xuất bản và hơn thế nữa
Dữ liệu có cấu trúc, sẵn sàng cho AI
Dữ liệu thời gian thực, quy mô lớn
Chỉ với một vài bước đơn giản để có được dữ liệu YouTube rõ ràng, có cấu trúc
Phân tích và truy cập tài nguyên video trực tiếp bằng ID video hoặc URL

Tải xuống nội dung video/âm thanh
Truy xuất bản ghi âm video
Tự động tải dữ liệu lên bộ nhớ đám mây được chỉ định của bạn
Tạo liên kết có thể chia sẻ và cung cấp quyền truy cập API
Cung cấp danh sách ID video, chỉ định đích lưu trữ đám mây. Chúng tôi sẽ tải xuống liền mạch và trả về cập nhật trạng thái. Một giải pháp tự động end-to-end không yêu cầu thiết lập.
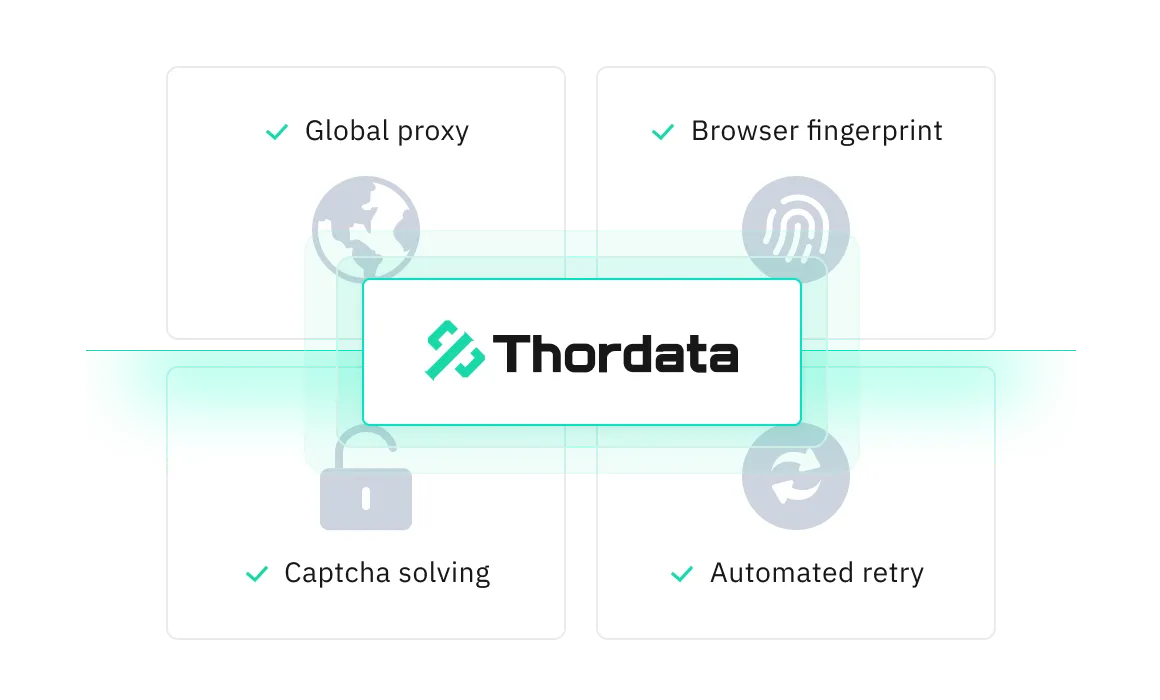
Lựa chọn và luân chuyển proxy được điều khiển bằng ML sử dụng nhóm proxy cao cấp từ 190 quốc gia.
Tiêu đề HTTP, JavaScript và dấu vết trình duyệt độc đáo đảm bảo khả năng phục hồi với nội dung động.
Thử lại tự động và vượt qua CAPTCHA để thu thập dữ liệu không bị gián đoạn.
Trích xuất dữ liệu từ nhiều trang cùng lúc với tối đa 10.000 URL mỗi lô.
Nhận dữ liệu qua lưu trữ đám mây như SFTP hoặc AWS S3, hoặc truy xuất kết quả thông qua API.
Đặt tần suất ưa thích của bạn để thu thập dữ liệu tự động theo thời gian tùy chỉnh, với kết quả được giao trực tiếp đến lưu trữ đám mây của bạn.
Loại bỏ việc bảo trì proxy và rắc rối về cơ sở hạ tầng. Không cần xây dựng hệ thống trình thu thập thông tin.
Dễ dàng tích hợp với hỗ trợ tùy chỉnh.
Nhận hỗ trợ chuyên nghiệp trong trường hợp có câu hỏi hoặc sự cố.
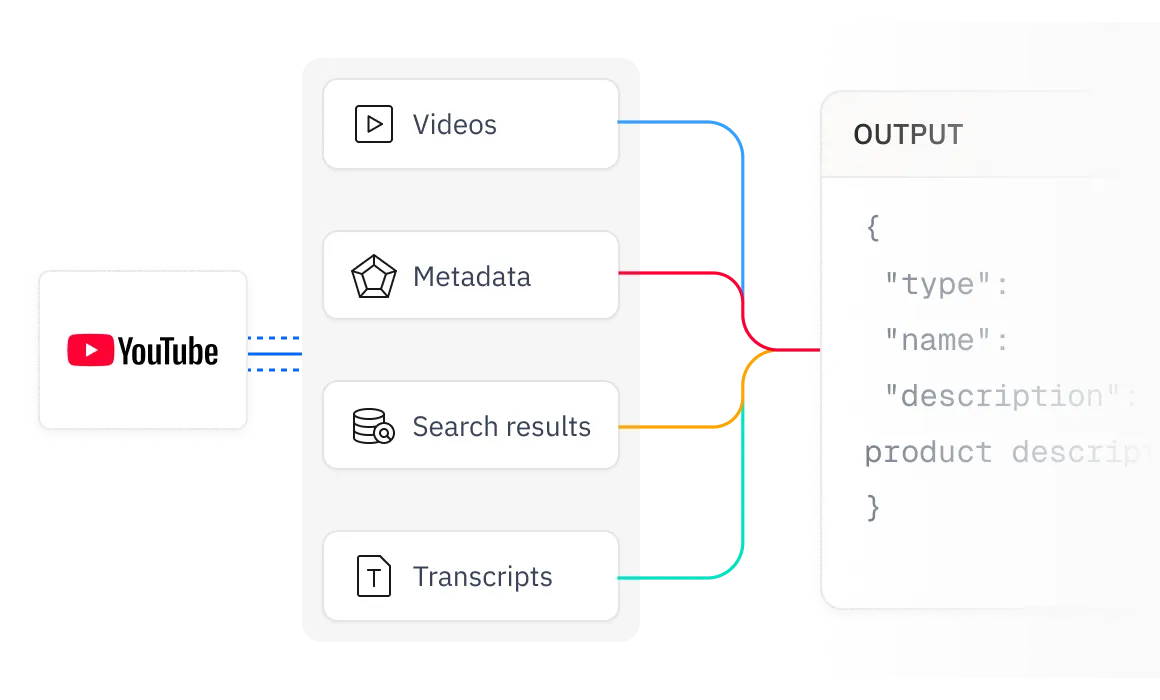
Chúng tôi cung cấp dữ liệu có cấu trúc, tương thích với AI, giúp video YouTube, bản ghi âm, phụ đề, siêu dữ liệu và kết quả tìm kiếm sẵn sàng để tích hợp liền mạch vào LLM, mô hình AI và quy trình làm việc phân tích.
Giảm khối lượng công việc làm sạch dữ liệu
Tích hợp LLM liền mạch
Có thể mở rộng và tự động hóa
Truy cập dữ liệu video chất lượng cao từ lưu lượng web thực tế toàn cầu
Không cần phát triển hoặc bảo trì trình thu thập thông tin hoặc trình duyệt
Vượt qua các hệ thống chống thu thập dữ liệu một cách dễ dàng
Tính hợp pháp phụ thuộc vào dữ liệu được trích xuất và mục đích sử dụng. Bạn phải tuân thủ mọi luật hiện hành, bao gồm bản quyền. Luôn tham khảo ý kiến luật sư, xem xét Điều khoản Dịch vụ hoặc có được sự cho phép thu thập dữ liệu trước.
Có. API Web Scraper của chúng tôi tích hợp với yt-dlp để vượt qua các rào cản trích xuất thông thường—tự động xử lý chặn, CAPTCHA và giới hạn tốc độ. Liên hệ với chúng tôi để được truy cập được phê duyệt dựa trên trường hợp sử dụng của bạn.
Truy cập siêu dữ liệu có cấu trúc như tiêu đề, lượt xem, thẻ, thời gian tải lên, thời lượng và tên kênh—lý tưởng cho đào tạo và phân tích.
Có. Lên lịch hoặc thu thập dữ liệu hàng loạt theo từ khóa, ID kênh/danh sách phát, với thời gian và tần suất có thể tùy chỉnh hoàn toàn.
Đối với yêu cầu nền tảng tùy chỉnh, hãy liên hệ với quản lý tài khoản Thordata chuyên trách của bạn để thảo luận các tùy chọn.