您的首個套餐免費!
首次住宅代理消費金額將全額返還至您的錢包餘額,最高可達900美元。
您的首個套餐免費!
首次住宅代理消費金額將全額返還至您的錢包餘額,最高可達900美元。
每日可新增影片數據
Youtube 全影片覆蓋
高品質原始種子
運行時間和全天候專家支援
無需擔心請求限制、存取攔截或 yt-dlp 故障,我們提供穩定高效的 PB 級影片數據採集服務,專為 AI 訓練定制
全格式影片/音頻
全自動批次下載
跨平台雲端儲存,數據自動同步
覆蓋 100+ 語言的轉錄文字
即時且大規模的數據
結構化、適用於 AI 訓練的數據(JSON 、CSV 、XLSX)
評論、內容、點讚數、發布日期、回覆等數據
即時與批次處理
品牌輿情監測
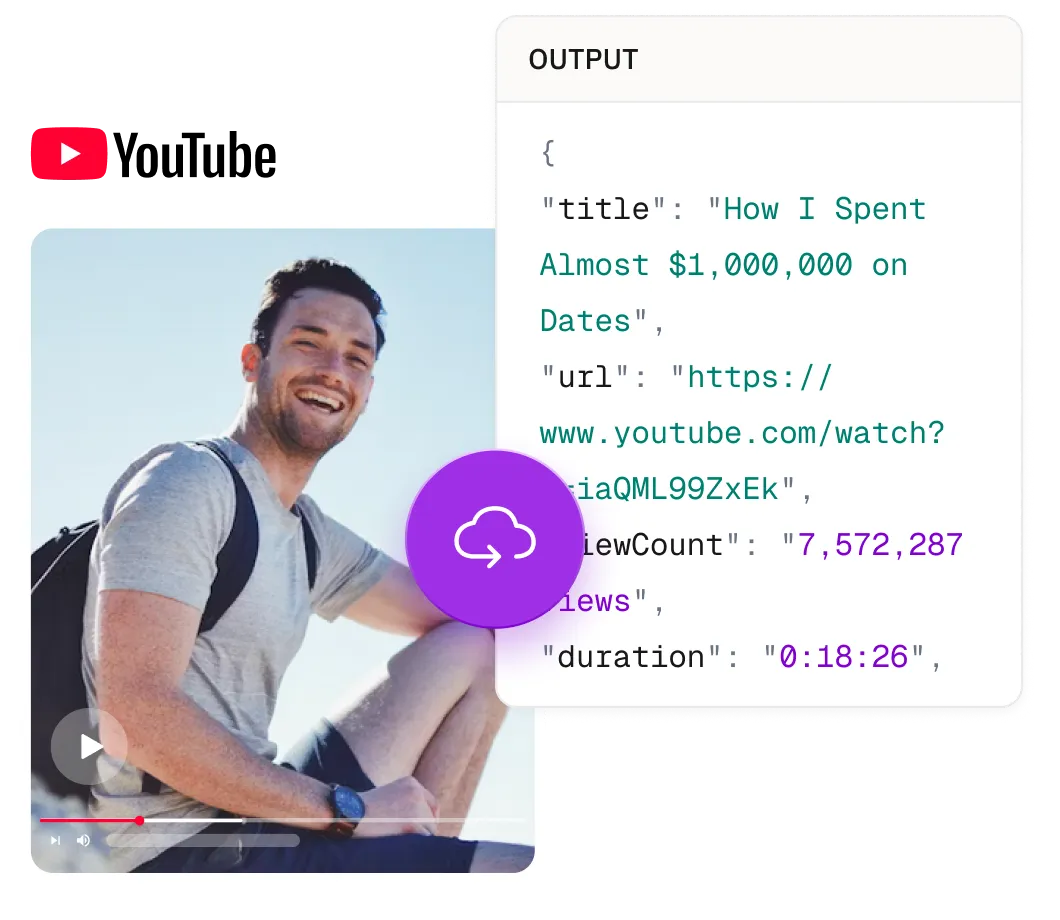
影片標題、頻道、觀看量、標籤和互動等數據
全自動化批次處理
可直接用於 AI 訓練
僅需簡單的步驟即可獲得清晰、結構化的 YouTube 數據。
通過視頻 ID 或 URL 直接解析並獲取視頻資源

下載影片 / 音頻內容
擷取影片轉錄文字
數據自動上傳至指定雲儲存
生成訪問鏈接並提供 API 接口
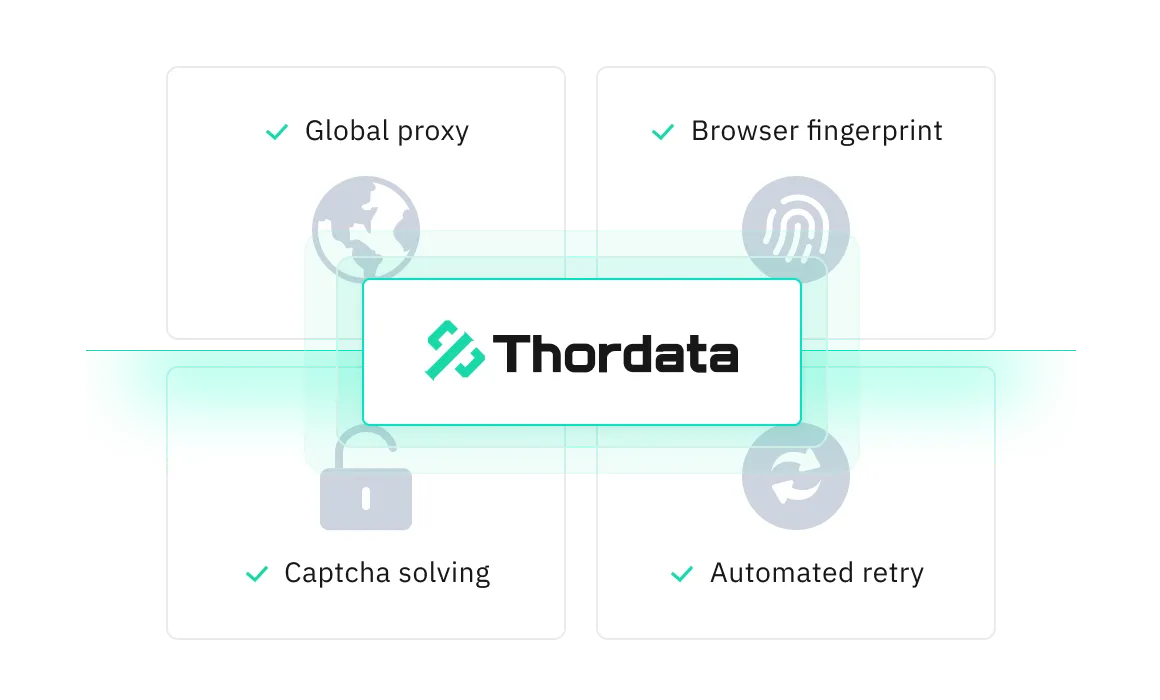
依托覆蓋 190 個國家的優質代理池,通過機器學習智能選擇並輪換代理 IP
模擬真實用戶的 HTTP 頭、JavaScript 及瀏覽器指紋,高效適應動態內容。
具備自動重試與驗證碼繞過功能,保障數據抓取不間斷。
支持同時從多個頁面抓取數據,每批最多可處理 10000 個 URL
支持將數據直接傳輸至 Amazon、GCS、阿里雲 OSS 等 S3 兼容存儲,也可通過 API 獲取結果。
可靈活設置任務頻率,按自定義時間或規則自動抓取,並將數據推送至雲存儲。
徹底告別代理維護與基礎設施解鎖,無需構建爬蟲系統。
輕鬆集成,支持大量請求,可按需定制。
全天候專業支持,及時解答疑問、解決問題。
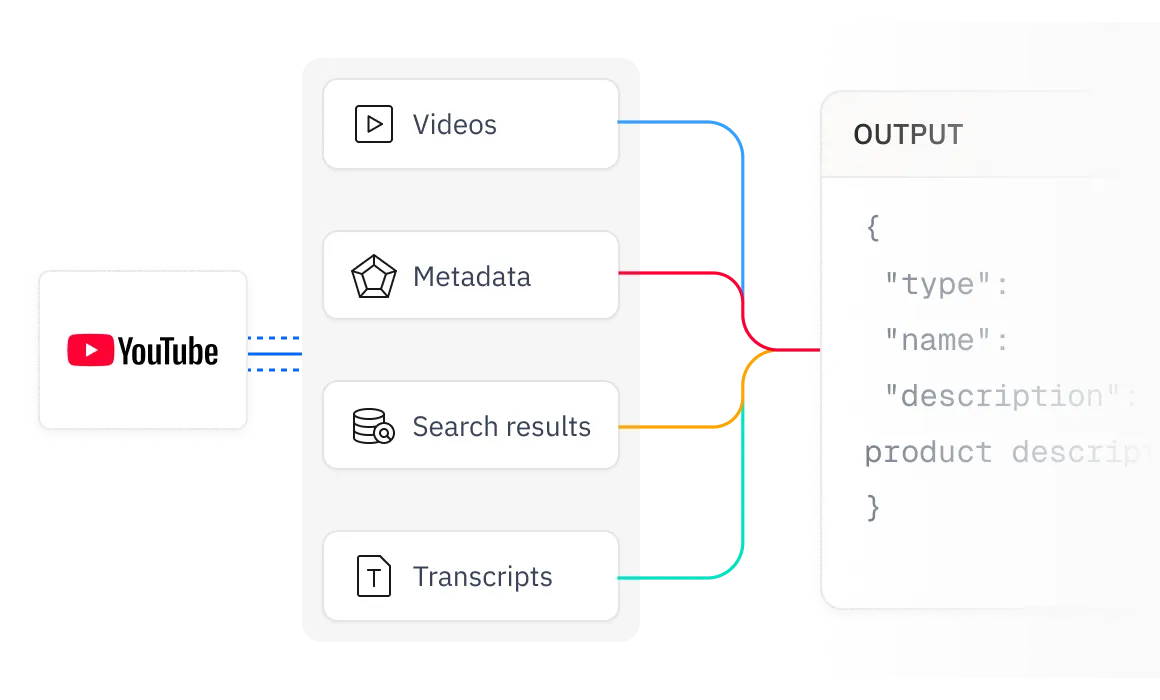
我們提供結構化、AI兼容的數據,使YouTube影片、文字記錄、字幕、元數據和搜索結果能夠無縫集成到LLM、AI模型和分析工作流中。
減少數據清洗工作量
無縫LLM集成
可擴展且自動化
從全球範圍獲取真實 Web 存取的高品質影片數據
無需開發與維護爬蟲和瀏覽器
繞過反爬系統
抓取 YouTube 數據的合法性主要取決於您擷取的具體數據以及使用方式。必須遵守所有相關法律法規,包括著作權法。在進行任何網路抓取活動之前,請諮詢法律顧問,查閱相應網站的服務條款或取得網路抓取許可。
是的,Thordata的網頁抓取API可與yt-dlp整合,以解決常見的數據擷取問題,該 API 可做為智慧代理層,透過自動處理存取攔截、驗證碼和速率限制等問題來增強 yt-dlp 的功能。請聯繫我們的專家團隊,說明您的具體使用場景,取得經審批的 yt-dlp 整合使用權限。
您可以取得來源影片的詳細中繼資料,包括標題、觀看次數、標籤、發布時間、長度、頻道名稱等。所有數據均為結構化格式,非常適用於訓練和分析。
支援批量抓取與定時任務,可靈活設定搜尋關鍵字、頻道 ID 或播放清單等來源,自訂抓取時間。實現靈活頻率抓取。
如果您需要從指定平台抓取數據,請聯繫 Thordata 為您提供的專屬客戶經理,共同討論您的需求。